Architecture
This page describes how SkyRL implements the Tinker API, including the system architecture, training and sampling request lifecycles, and concurrency model.
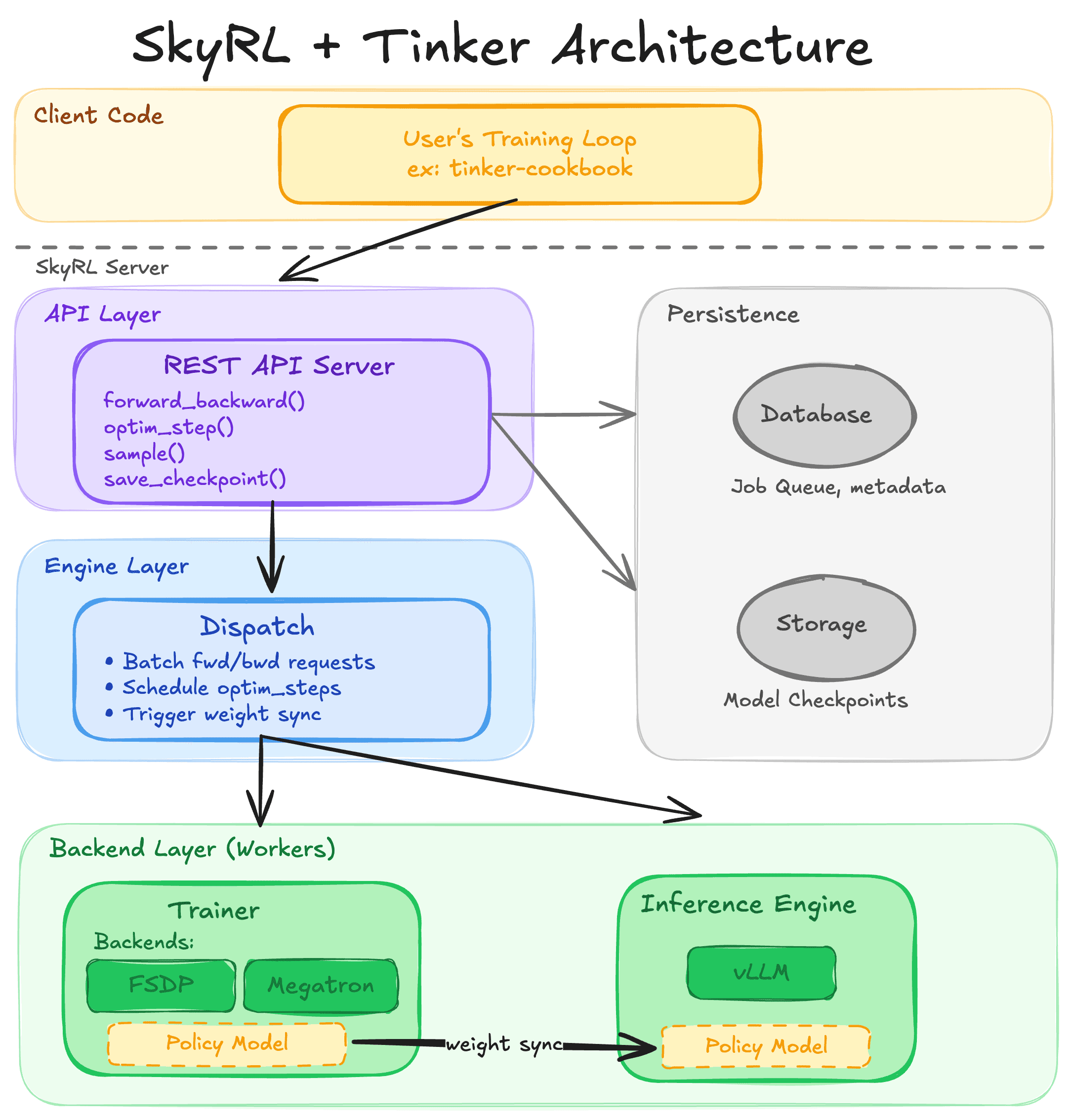
System Architecture
The integration is organized in three high-level layers:
- API Layer (
skyrl.tinker.api) - FastAPI HTTP server that accepts Tinker API requests, stores them in a database, and returns future IDs for async polling - Engine Layer (
skyrl.tinker.engine) - Background subprocess that polls the database, batches pending requests, and dispatches them to the backend - Backend Layer (
skyrl.backends) - Translates Tinker operations into training and inference calls, managing Ray workers, FSDP/Megatron training, and vLLM inference
Model Creation
The Tinker call create_lora_training_client() triggers the full initialization of the SkyRL backend, spinning up training and inference workers, loading the base model (optionally with LoRA adaptors), and initializing weight sync state like NCCL transfer channels
Training
Training requests (forward_backward, optim_step, forward) go through the following lifecycle:
Client (tinker SDK)
│
▼
API Server (FastAPI)
│ Writes request to SQLite DB
▼
Background Engine (subprocess)
│ Polls DB, batches requests
▼
SkyRL-Train Backend
│ Converts Tinker batch → SkyRL TrainingInputBatch
▼
RayPPOTrainer.dispatch
│ Distributes work across Ray workers
▼
GPU Workers (FSDP or Megatron)
│ Execute forward/backward/optim
▼
Results aggregated → DB updated → Client polls futureforward_backward()
Calls trainer.dispatch.forward_backward("policy", batch, loss_fn=loss_fn) which distributes computation across FSDP/Megatron workers. The dispatch returns:
loss_fn_outputs: Per-example dicts containinglogprobsandelementwise_loss- Aggregate metrics:
loss,policy_loss,policy_entropy,response_length
forward()
Calls trainer.dispatch.forward("policy", batch) for a gradient-free forward pass. Returns only logprobs per example (no loss computation).
optim_step()
Calls dispatch.optim_step("policy") to apply accumulated gradients.
Sampling
Sampling requests (sample) go through the following lifecycle:
Client calls sample()
│
▼
SkyRL-Train Backend
│ Converts Tinker SamplingParams → vLLM params
▼
InferenceEngineClient
│ Distributes prompts across vLLM engines
▼
Inference Workers (vLLM)
│ Generate tokens with logprobs
▼
Results aggregated → GeneratedSequence objects returnedThe sample() call is a fairly lightweight wrapper around SkyRL-Train's vLLM inference engines. The backend translates Tinker SamplingParams to vLLM format (e.g., stop_strings → stop, stop_tokens → stop_token_ids) and delegates prompts to the InferenceEngineClient, which handles load balancing and sticky routing across vLLM workers.
Weight Sync
Training workers and inference engines hold separate copies of the model weights. After training updates the policy, the client must explicitly call save_weights_for_sampler() to broadcast the new weights to the inference engines before sampling. Multiple training steps (forward_backward + optim_step) can accumulate before a single sync.
Client calls save_weights_for_sampler()
│
▼
SkyRL-Train Backend
│
▼
RayPPOTrainer.dispatch.save_weights_for_sampler()
│ NCCL broadcast
▼
Training Workers ──→ Inference Engines (vLLM)
(source weights) (receive updated weights)Weight Sync Modes: Ephemeral vs Persistent
The Tinker SDK provides two paths for syncing weights to inference engines, depending on whether the caller needs a durable checkpoint on disk.
Persistent mode
Triggered by save_weights_for_sampler(name="..."). This syncs the latest training weights to the inference engines and writes a full HuggingFace model checkpoint to disk. The call returns a tinker:// path that can be loaded later via load_checkpoint. Use persistent mode for checkpointing at milestones (e.g., end of epoch, best-so-far evaluation score).
Ephemeral mode
Triggered by save_weights_and_get_sampling_client(name="..."). This syncs weights to the inference engines only and skips the disk write entirely. Instead of returning a checkpoint path, it returns a sampling client directly. Use ephemeral mode in hot RL loops where you sync weights every batch but do not need to persist every iteration.
How the server distinguishes them
The Tinker SDK sends a sampling_session_seq_id field when using the ephemeral path. When the server sees this field (and no explicit checkpoint path or name), it skips the expensive disk write.
Why it matters
Persistent saves can be very expensive because they write full model weights to disk on every call. In RL training loops that sync weights every batch, ephemeral mode avoids this overhead entirely. In typical RL loops (e.g., tinker-cookbook's rl_loop), every iteration uses ephemeral mode before sampling, and persistent saves are reserved for periodic checkpointing.
Multiple LoRA tenants
On the Megatron backend, SkyRL supports multiple LoRA adapters trained and sampled concurrently against a single server. Each tenant's adapter weights and optimizer state live in pinned-CPU slots; the live GPU adapter is swapped on demand at the top of every per-model dispatch entry point (forward, forward_backward, optim_step, save_weights_for_sampler). On the inference side, vLLM serves each tenant's adapter by model_id after save_weights_for_sampler registers it via load_lora_adapter. See Multi-tenancy for the design and operator contract.
Full-parameter fine-tuning and the FSDP backend remain single-tenant — calling create_model a second time on those paths returns an error.
Checkpointing
The backend supports two checkpoint types:
- Full checkpoint (
save_checkpoint/load_checkpoint): Saves model weights, optimizer state, and LR scheduler as an uncompressed tar archive. Used for resuming training. - Sampler checkpoint (
save_weights_for_sampler/save_weights_and_get_sampling_client): Syncs weights to inference engines. In persistent mode, also exports a HuggingFace model to disk; in ephemeral mode, skips the disk write (see Weight Sync Modes above).
Loss Functions
The following loss functions are validated through the Tinker API:
| Loss Function | Description | Use Case |
|---|---|---|
cross_entropy | Standard next-token prediction loss | Supervised fine-tuning |
importance_sampling | Off-policy policy gradient: -(exp(logp - old_logp) * advantage) | RL training (GRPO, REINFORCE) |
SkyRL-Train's PolicyLossRegistry also contains additional loss functions (regular, dual_clip, gspo, sapo, cispo, clip_cov, kl_cov) used by SkyRL's native trainer. These are not yet wired through the Tinker data conversion path, which does not currently populate the required advantages and old_log_probs fields in the training batch for these loss types.
Concurrency Model
The Tinker API is inherently asynchronous:
- Clients submit requests and receive a
request_id(future) - The background engine batches compatible requests (e.g., multiple
forward_backwardcalls for the same model) - Barrier operations (
optim_step,load_checkpoint) block until prior operations complete - Clients poll
retrieve_futureto get results
This design allows the engine to batch small requests for better GPU utilization and to pipeline operations when possible.
Batching
Tinker represents training data as Datum objects with a ModelInput (containing one or more EncodedTextChunks of token IDs) and loss_fn_inputs (a flexible dictionary of TensorData fields whose keys vary by loss function — e.g., target_tokens and weights for SFT, or target_tokens, logprobs, advantages, and mask for RL). The backend converts these to SkyRL's TrainingInputBatch format:
- Left-pads sequences to uniform length (SkyRL-Train expects padded tensors)
- Shifts tokens: Tinker pre-shifts inputs/targets, but SkyRL-Train shifts internally, so the backend appends the last target token to reconstruct full sequences
- Builds
attention_mask,loss_mask, andresponse_masktensors from token weights
The engine layer also batches multiple client requests together before passing them to the backend.