SkyRL System Overview
SkyRL breaks the RL stack into modular components and provides public APIs for each of them.
Specifically, as shown in figure below, SkyRL separates training into two major components, Trainer and Generator, and the Generator is further divided into InferenceEngine and Environment, with a single Controller managing setup and execution of each component.
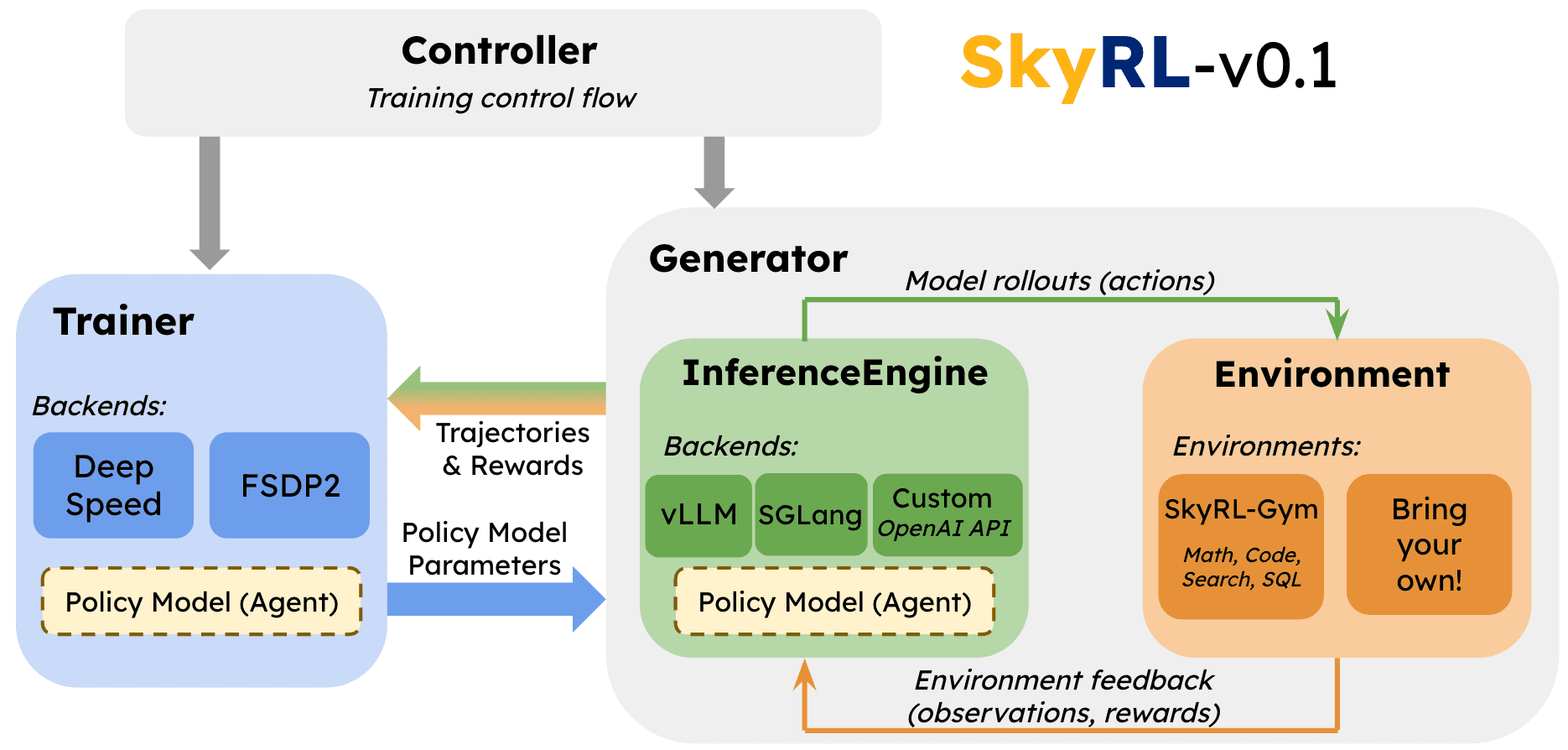
The components' responsibilities are as follows:
Trainer
Performs the optimization steps based on configured RL algorithm. Updates model parameters based on generated trajectories and their assigned rewards.
-
PPORayActorGroup: Our abstraction for a group of training workers (as Ray actors) that jointly execute operations for a given model (e.g., policy model, critic model, etc.).
Generator
Generates complete trajectories and computes their rewards. The Generator encompasses both the InferenceEngine (to get model completions) and Environment (to execute actions) as well as custom agentic or data generation logic build around model inference, such as context management, sampling methods, or tree search.
InferenceEngine
Executes inference on the policy model to produce model outputs (i.e., the RL agent's actions). Typically, multiple InferenceEngines are deployed to process prompts in parallel. For more details, refer to the inference architecture page.
Environment
Presents a task for the policy model to solve, and provides the logic for executing the policy's actions (i.e., model outputs) and computing the resulting observations and rewards.
-
SkyRL-Gym, our ready-built library of tool-use environments
Controller
Manages physical placement, initialization, and control flow of training execution for each of the above components.
- The training control loop currently sits in trainer.py
- It is a WIP to move the control loop to a separate component for even greater flexibility.